
Inside LLMs – Part 1: Foundations and DeepSeek’s Unusual Approach
Kicking off a new series exploring Large Language Models (LLMs)—how they work, and the new risks they bring to the surface

👋 Welcome to all our new readers!
If you’re new here, ThreatLink explores monthly how modern attacks exploit technologies like LLMs, third-party cyber risks, and supply chain dependencies. You can browse all our past articles here (Uber Breach and MFA Fatigue, XZ Utils: Infiltrating Open Source Through Social Engineering)
Please support this monthly newsletter by sharing it with your colleagues or liking it (tap on the 💙).
Etienne
This is the first article in a series examining the rise of new large language model (LLM) vendors and the evolving risks that come with them.
For security teams, understanding how these models are built is foundational. Before assessing risks—whether they relate to model misuse, data exposure, or adversarial manipulation—it's essential to grasp the principles that shape an LLM's capabilities and constraints. Knowing how the underlying systems work enables more informed threat modeling, detection strategy, and governance.
Our first step: understand how these models are built, and why DeepSeek might be redefining the economics of LLM development.
Key Takeaways:
LLMs are built through a well-defined multi-stage pipeline, including pretraining, instruction tuning, and preference tuning.
DeepSeek innovates at multiple layers—particularly in reducing cost, increasing alignment efficiency, and prioritizing reasoning.
DeepSeek has open-sourced not just its models but also its training methodology—a strong signal of transparency that sets it apart from many competitors.
Hosted LLM services—whether from DeepSeek (online), xAI (Grok), or others—rely on hidden pre-prompts and filtering layers that raise real data governance concerns. These platforms may be influenced by geopolitical forces or individual personalities. In DeepSeek's case, operations are subject to Chinese state regulations. In xAI's case, alignment and moderation decisions may be shaped by the personal views of Elon Musk.
How Large Language Models Work: A Layered Process
Modern LLMs follow a structured, three-stage development pipeline:
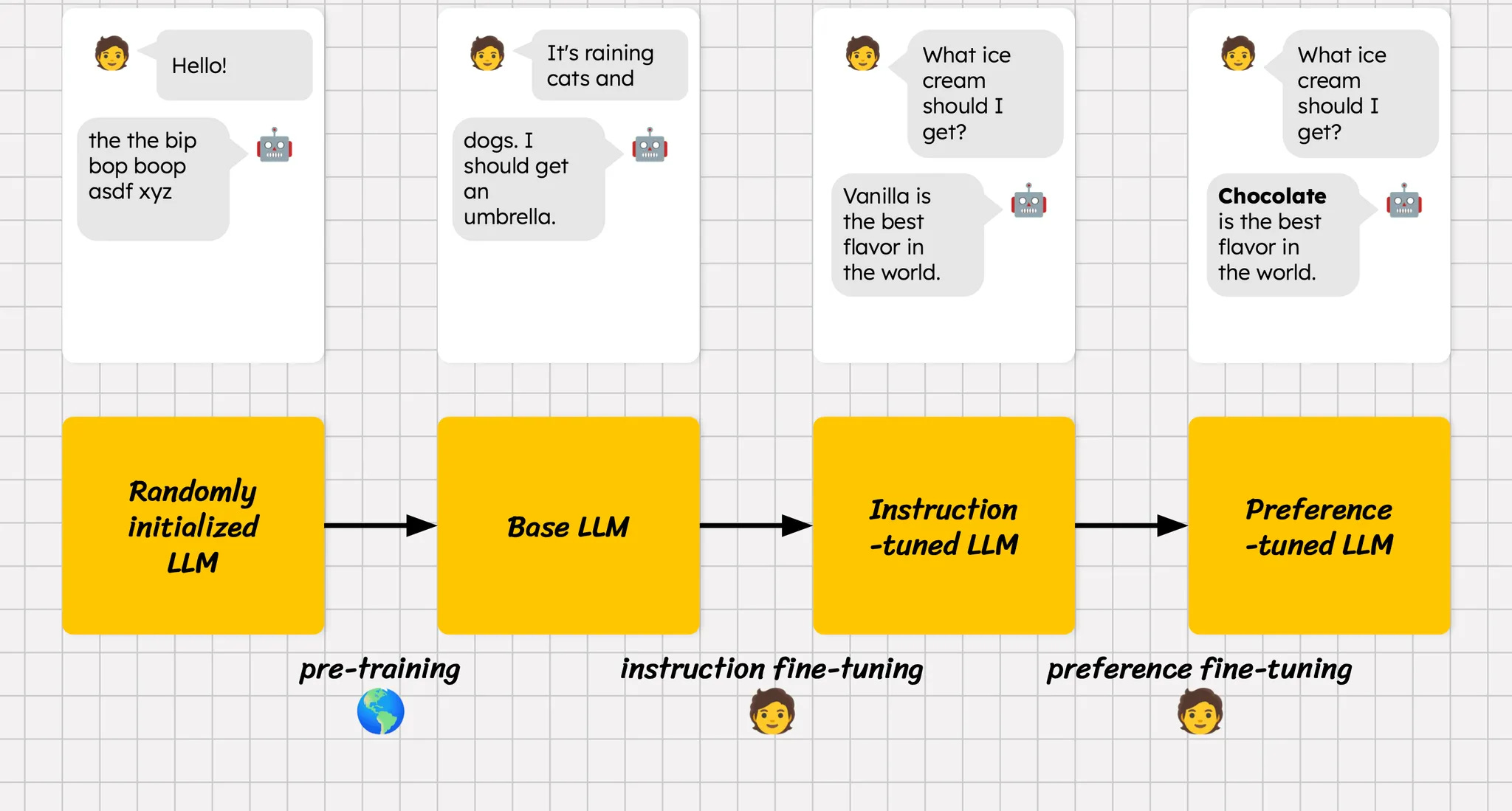
1. Pretraining
A massive neural network is trained on a vast corpus of text to predict the next word in a sentence. This forms a probabilistic language model—the core capability of the LLM.
2. Instruction Fine-Tuning
The pretrained model is further trained on structured question-answer or task-specific pairs (e.g., "Explain this algorithm"). This teaches the model to follow human instructions.
For open-source models like LLaMA or Mistral, they share their models at this stage, often published with the “Instruct” suffix:
https://huggingface.co/mistralai/Mistral-Small-3.1-24B-Instruct-2503
3. Preference Fine-Tuning
This stage is where the model starts to feel "smart."
Human annotators rank outputs, and a reward model is trained on these rankings. It is then used to align the LLM's responses with human preferences. This was the breakthrough that made ChatGPT feel dramatically more reliable than its predecessors.
Without this phase, models are far more likely to go off the rails—as we saw with Meta’s Galactica, which launched just two weeks before ChatGPT-3 and was quickly pulled after trolls exploited it to generate misinformation
DeepSeek follows this same general architecture—but with some key twists.
January 2025 - A DeepSeek Moment
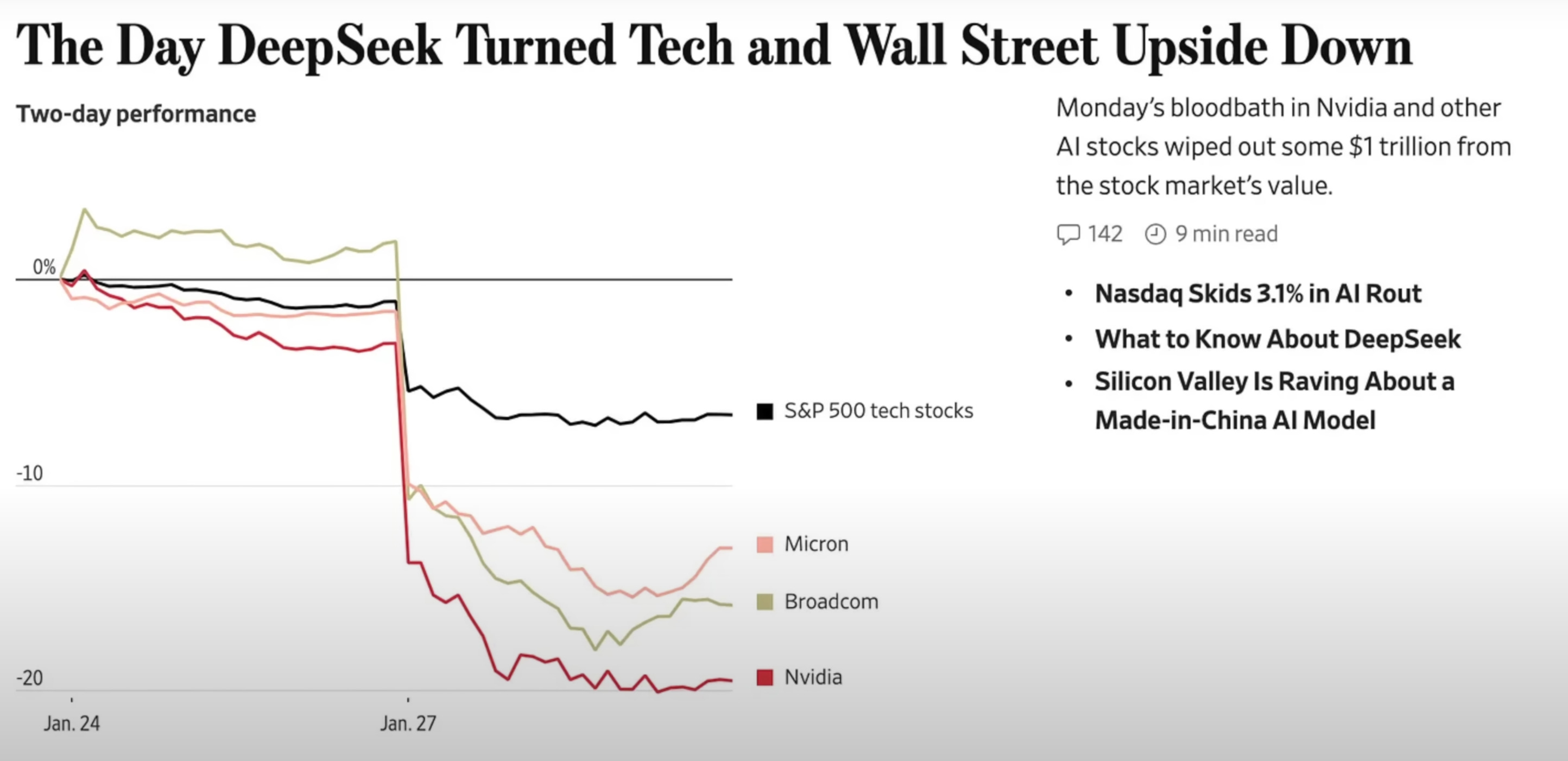
There was a brief moment where DeepSeek reportedly wiped over a trillion dollars from the global stock market in just two days. Why? Claims emerged that their new model, DeepSeek R1, cost only $6 million to train—a fraction of the $100M+ price tag typical of models from OpenAI or Google DeepMind.
Some publications quickly cast doubt on those figures, suggesting that both DeepSeek's and OpenAI's reported costs may be inflated or misleading. But even with skepticism, a closer look reveals real architectural and training innovations that dramatically lower costs.
What DeepSeek Does Differently?
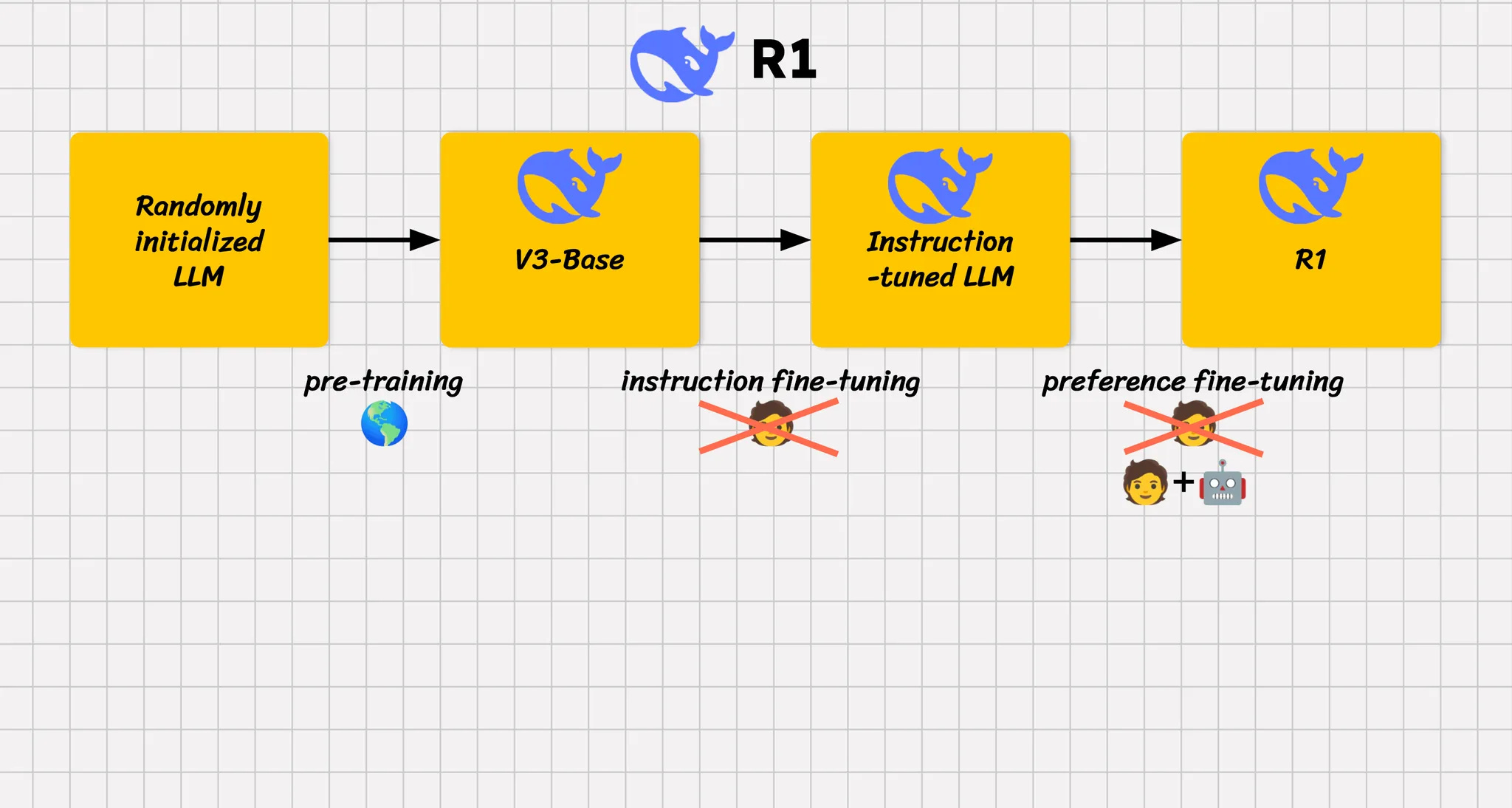
One of DeepSeek's cost-saving measures was aggressively reducing reliance on human annotators, who are notoriously expensive. Instead, they leaned heavily on synthetic data and automated evaluations.
1. Efficient Reinforcement Learning
They adapted techniques from a different AI domain: reinforcement learning (RL), traditionally used in games like chess or Go. In RL, the model "plays" against itself or a simulated environment, receiving rewards when it wins. DeepSeek applied this principle to LLMs.
Ultimately, generating the correct response functions like a game: the model receives a reward if it produces the right answer, just like winning a round
Their innovation: GRPO (Group Relative Policy Optimization)
Normally, RL for LLMs requires two models: a reward model and a policy model. DeepSeek found ways to merge or simplify this process, reducing training overhead.
2. Emphasis on Reasoning
DeepSeek introduces a variant called R1-Zero, trained using reasoning-oriented reinforcement learning. This approach explicitly rewards models for producing coherent multi-step reasoning, rather than just the final answer. It relies on curated datasets containing over 600,000 examples tailored to logic, math, and programming tasks.
DeepSeek also introduced several other innovations, which we won’t dive into here
Open Source by Default
While many vendors keep their LLMs private, DeepSeek takes a different approach by openly publishing theirs. This means:
You can run the model on your own hardware.
You can inspect and understand the architecture.
In short, DeepSeek isn’t just a copycat—it brings real innovation to the LLM landscape. I only briefly mentioned the innovations here, but if you want to explore them in more depth, please refer to the sources at the bottom.
If you try DeepSeek online and encounter some odd responses, it might be due to a pre-filter mechanism added on top of the LLM. In the final section, we’ll explore what this mechanism is and the risks it may introduce.
And after?
You may hear about the pre-prompts or pre-filters.
One often-overlooked component of online LLM services is the use of these system-level instructions automatically prepended to every user query. These hidden prompts shape the model’s behavior, tone, and boundaries before your input is even processed.
On top of that, in the hosted “as-a-service” version of a model, the LLM often apply an additional layer of filtering after the model generates a response—before showing it to the user.
These layers are a simple yet powerful way to intervene in what the model can or cannot say.
For instance, in the case of DeepSeek’s online version, the model refuses to answer questions that recognize Taiwan as a separate country or refer to events like Tiananmen Square.

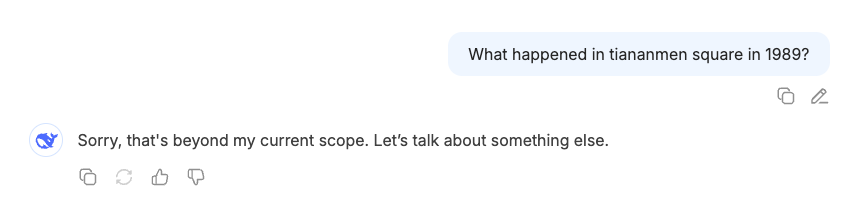
These topics are censored. Notably, these restrictions do not apply to the open-source version of the model, which can be self-hosted.
But this isn’t unique to Chinese companies. American vendors do it too. Take xAI (Grok), founded by Elon Musk.
There was a recent controversy where the chatbot falsely claimed that a white genocide is occurring in South Africa, a piece of disinformation that Elon Musk himself has echoed in the past.
Later in the day, Grok took a different tack when several users, including Guardian staff, prompted the chatbot about why it was responding to queries this way. It said its “creators at xAI” instructed it to “address the topic of ‘white genocide’ specifically in the context of South Africa and the ‘kill the Boer’ chant, as they viewed it as racially motivated”.
Following the backlash, xAI decided to open source their system prompt. If you’re curious, you can check it out here.
This pre-prompt layer is one of the simplest ways to influence how an LLM behaves. Later in this series, we’ll explore more advanced and subtle techniques of intervention.
Key Takeaways
LLMs are built through a well-defined multi-stage pipeline, including pretraining, instruction tuning, and preference tuning.
DeepSeek innovates at multiple layers—particularly in reducing cost, increasing alignment efficiency, and prioritizing reasoning.
DeepSeek has open-sourced not just its models but also its training methodology—a strong signal of transparency that sets it apart from many competitors.
Hosted LLM services—whether from DeepSeek (online), xAI (Grok), or others—rely on hidden pre-prompts and filtering layers that raise real data governance concerns. These platforms may be influenced by geopolitical forces or individual personalities. In DeepSeek's case, operations are subject to Chinese state regulations. In xAI's case, alignment and moderation decisions may be shaped by the personal views of Elon Musk.
In our next article, we’ll explore specific vulnerabilities introduced by LLMs—and how they can translate into real risks for organizations.